ChatGPT semble interroger Google, mais les résultats divergent
Pour le découvrir, nous avons effectué une série d’expériences afin d’analyser le lien entre les URLs citées par ces assistants AI et les résultats de Google pour les mêmes sujets.
Nous avons testé des requêtes longues (des requêtes très précises similaires à celles que vous pourriez entrer dans ChatGPT) et des requêtes fan-out (des requêtes de longueur moyenne dérivées des premières). Actuellement, nous testons des mots-clés courts—des termes très courts et spécifiques.
Les mots-clés courts illustrent de manière claire comment les citations des AI s’alignent avec les résultats de Google.
Sur la base de trois études distinctes, notre conclusion est que ChatGPT (et des systèmes similaires) ne se contentent pas de reprendre les URLs directement de Google ou Bing. Ils appliquent des étapes de traitement supplémentaire avant de citer leurs sources.
Même en examinant les requêtes fan-out—les réelles requêtes envoyées par ces systèmes aux moteurs de recherche—le chevauchement entre les citations AI et celles des moteurs de recherche était étonnamment faible.
En d’autres termes, bien que ChatGPT puisse puiser dans l’index de recherche de Google, il semble appliquer sa propre couche de sélection qui filtre et réorganise les liens qui apparaissent.
Il ne suffit donc pas de bien classer les requêtes fan-out pour être cité. Des facteurs supplémentaires, échappant au contrôle des éditeurs, influencent quelles URLs sont mises en avant.
Méthodologie
Les différents types de requêtes nous renseignent sur la manière dont les assistants AI manipulent l’information.
Dans nos recherches précédentes, le data scientist d’Ahrefs, Xibeijia Guan, a analysé le chevauchement des citations entre les AI et les résultats de recherche pour des requêtes longues et en éventail, en utilisant l’outil Ahrefs Brand Radar.
Cette fois, elle a pris un échantillon de 3 311 termes classiques de type SEO, couvrant les intentions informatives, commerciales, transactionnelles et de navigation.
| Exemple de requête | Informatif | Commercial | Transactionnel | Navigationnel |
|---|---|---|---|---|
| 1 | cincinnati bearcats basketball | meilleure carte de crédit récompenses | piscines à vendre | connexion onedrive |
| 2 | protéines dans les crevettes | barre de son pour télévision | acheter une robe | support client verizon |
| 3 | qu’est-ce que la cybersécurité | sauna à domicile | acheter un domaine | papier toilette costco |
Chaque mot-clé a été analysé via ChatGPT, Perplexity, et les 100 meilleurs SERPs de Google pour déterminer le chevauchement des citations entre l’AI et la recherche.
Seulement 10% des résultats courts de ChatGPT figurent dans le top 10 de Google
On pourrait s’attendre à ce que les requêtes courtes correspondent étroitement aux résultats de Google, car elles représentent la manière classique de rechercher.
Cependant, ce n’est pas vraiment le cas.
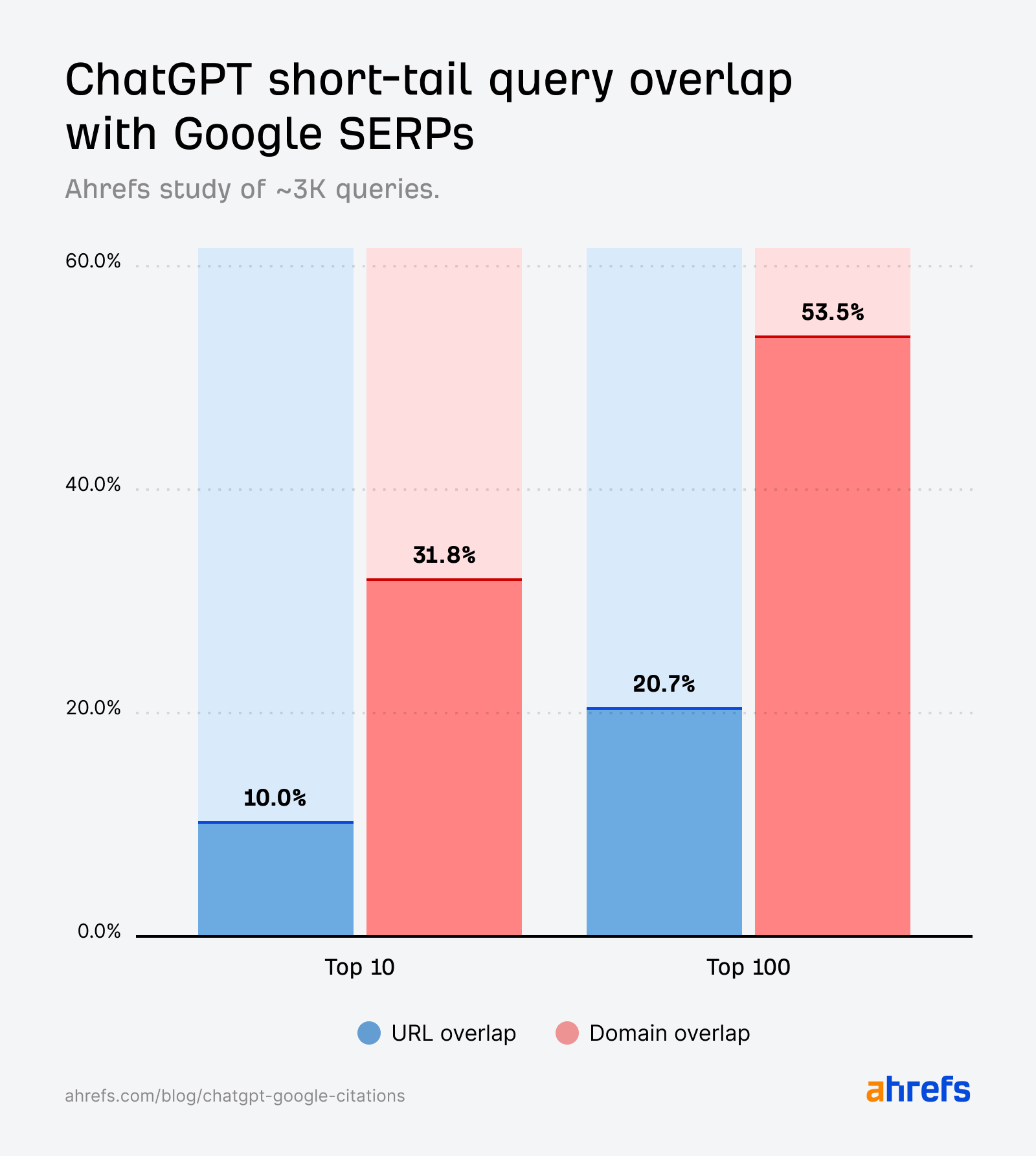
Bien que le chevauchement pour les requêtes courtes (10%) soit légèrement supérieur à celui des requêtes en éventail (6,82%), il reste bien inférieur à ce qu’on attendrait s’il reflétait directement les SERPs.
Cela est d’autant plus surprenant que nous avons confirmation qu’OpenAI et Perplexity ont extrait des résultats de Google via un fournisseur tiers.
Il est possible que nous voyions plus de chevauchement si notre étude se concentrait uniquement sur les requêtes « en temps réel » (par exemple, actualités, sports, finances), car ce sont les types de requêtes que ChatGPT consulterait sur Google.
65% des résultats courts de Perplexity figurent dans le top 10 de Google
Les citations de Perplexity s’alignent étroitement sur les résultats de recherche de Google pour les requêtes courtes.
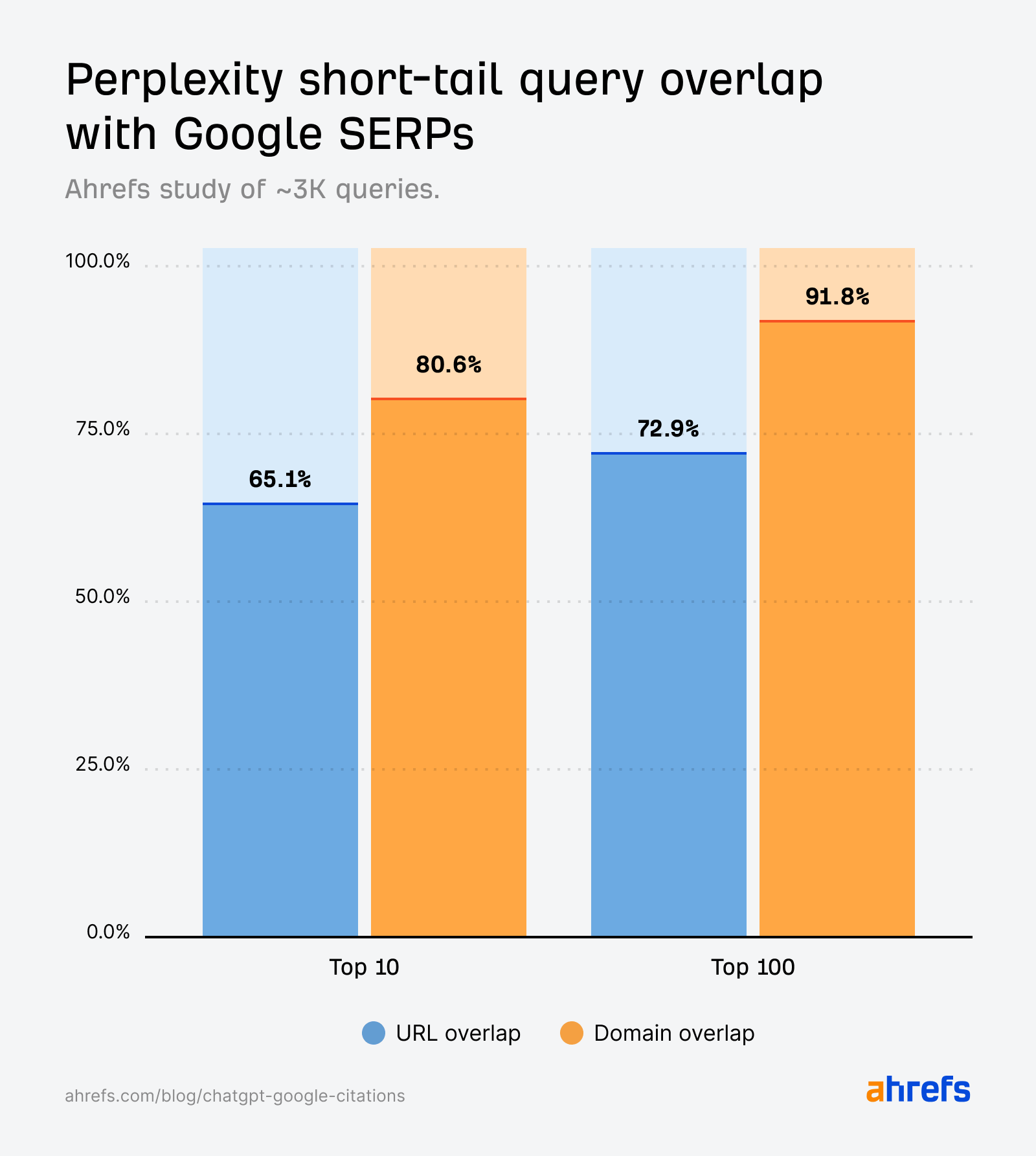
À la différence de ChatGPT, le chevauchement ne se manifeste pas seulement au niveau du domaine—la plupart des pages citées par Perplexity sont aussi les mêmes URLs classées dans le top 10 de Google.
Cela reflète les résultats de notre étude sur les requêtes longues, où les réponses de Perplexity ressemblaient le plus aux résultats de Google, renforçant sa conception en tant que moteur axé sur les citations.
ChatGPT cite les domaines classés trois fois plus que les pages classées
Le chevauchement au niveau des domaines est systématiquement plus élevé que celui des URLs, ce qui suggère que ChatGPT et Perplexity citent les mêmes sites que Google—mais pas exactement les mêmes pages.
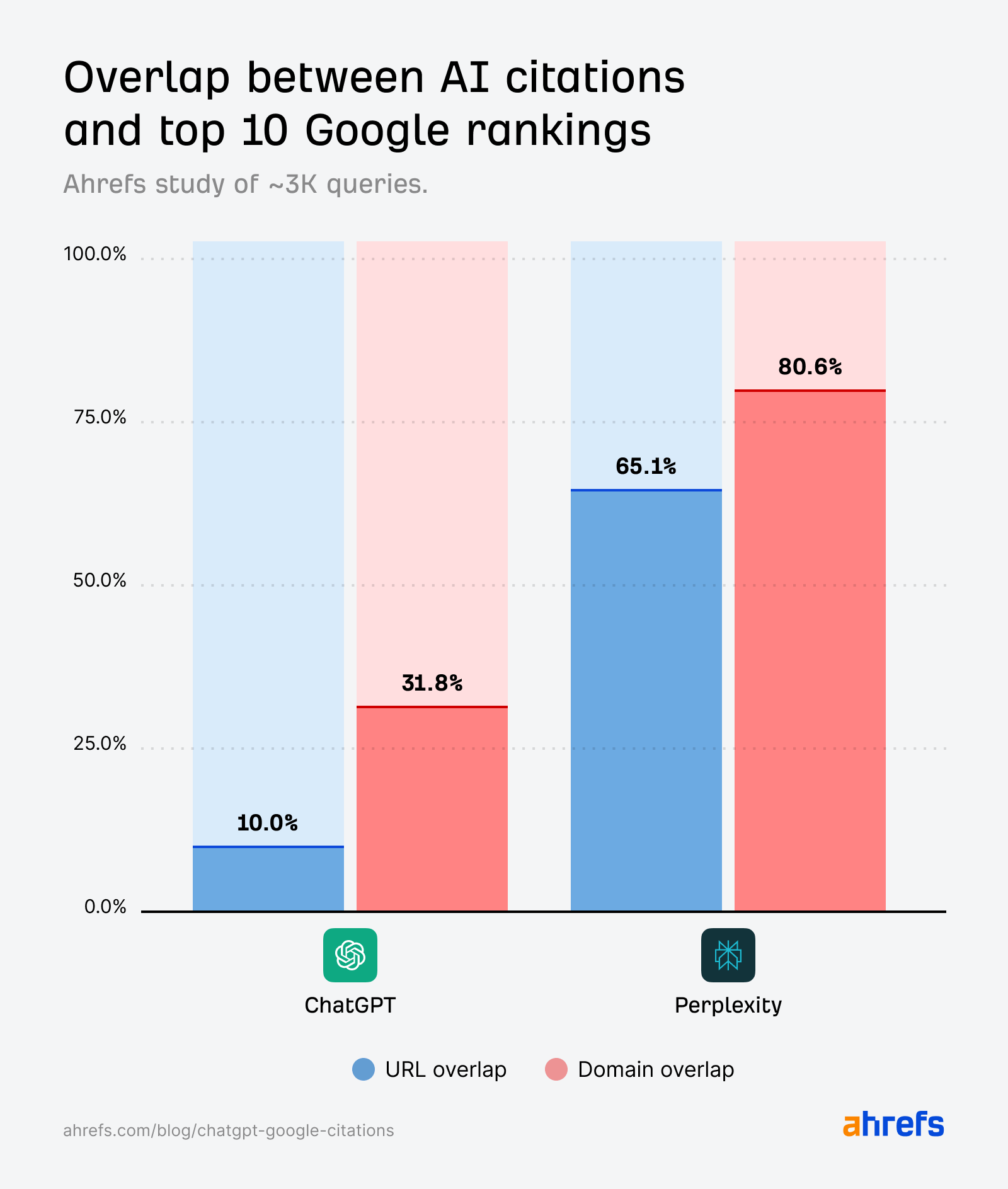
Chez ChatGPT, l’écart domaine-URL est particulièrement large: 31,8% contre 10%.
En d’autres termes, ChatGPT cite les domaines classés environ trois fois plus que les pages classées.
Il se pourrait que ChatGPT sélectionne des pages différentes des mêmes domaines que Google.
Par exemple, Google cite une page de ahrefs.com/writing-tools/, alors que ChatGPT trouve une meilleure « correspondance » sur ahrefs.com/blog/ et cite une autre.
Si cela est vrai, cela renforce l’importance de créer du contenu en cluster—en optimisant plusieurs pages pour différents intents de sujet, pour avoir les meilleures chances d’être trouvé.
Une autre possibilité est que les deux s’appuient sur le même pool de domaines autoritaires, mais ne s’accordent pas sur les pages exactes.
Évaluer le contenu en cluster dans l’AI et la recherche
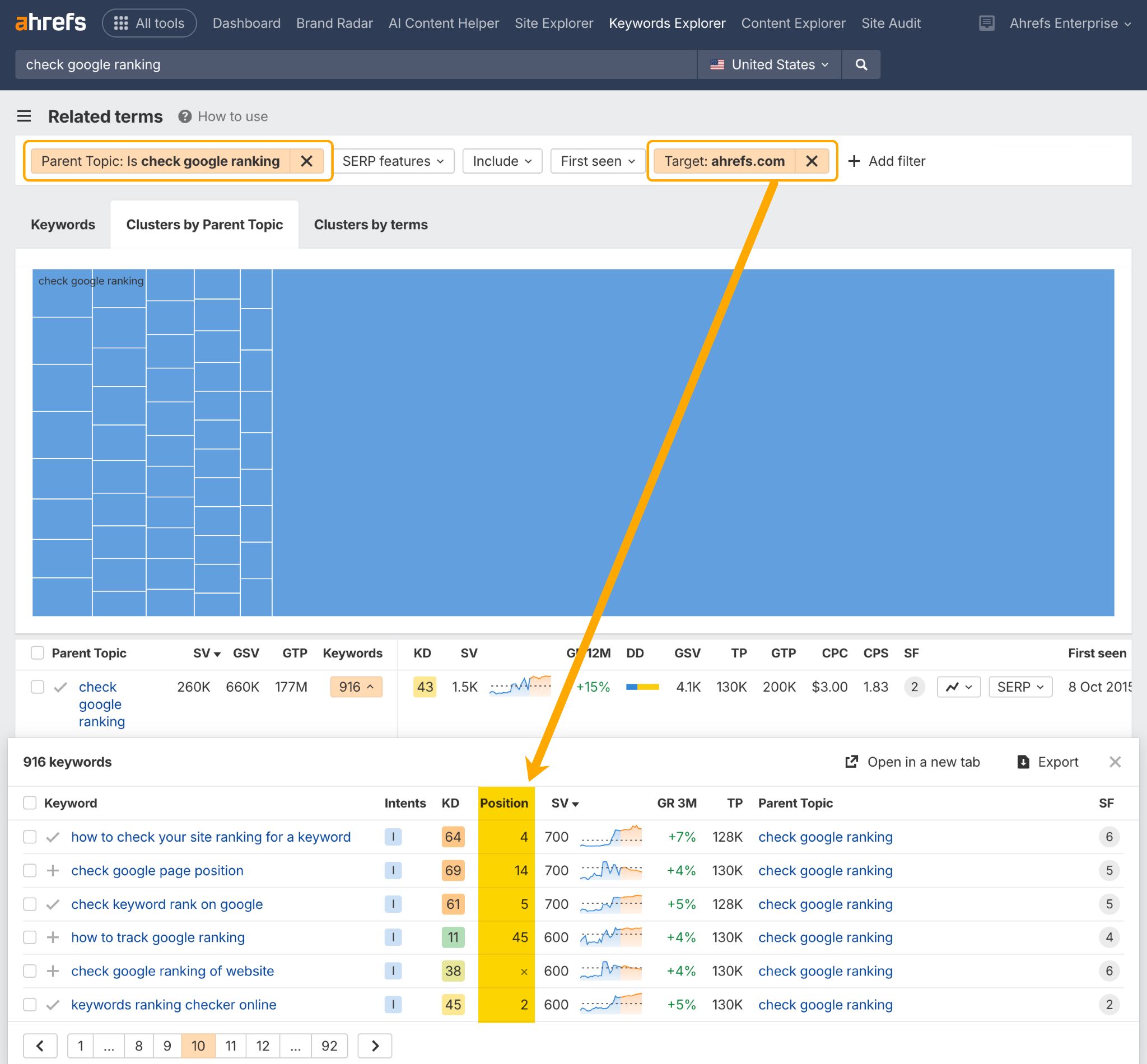
Vous pouvez vérifier la performance SEO de votre contenu en cluster dans le rapport sur les Termes Associés dans Ahrefs Keywords Explorer.
Cela vous montrera si et où vous vous classez sur un ensemble de mots-clés associés.
Ajoutez simplement un filtre de Sujet Parent, et un filtre Cible contenant votre domaine.
Ensuite, rendez-vous sur Ahrefs Brand Radar pour vérifier la performance AI de votre contenu en cluster.
Analysez les URLs individuelles via le rapport Pages Citée dans Ahrefs Brand Radar pour voir si votre contenu en cluster est cité par des assistants AI tels que ChatGPT, Perplexity, Gemini, et Copilot.
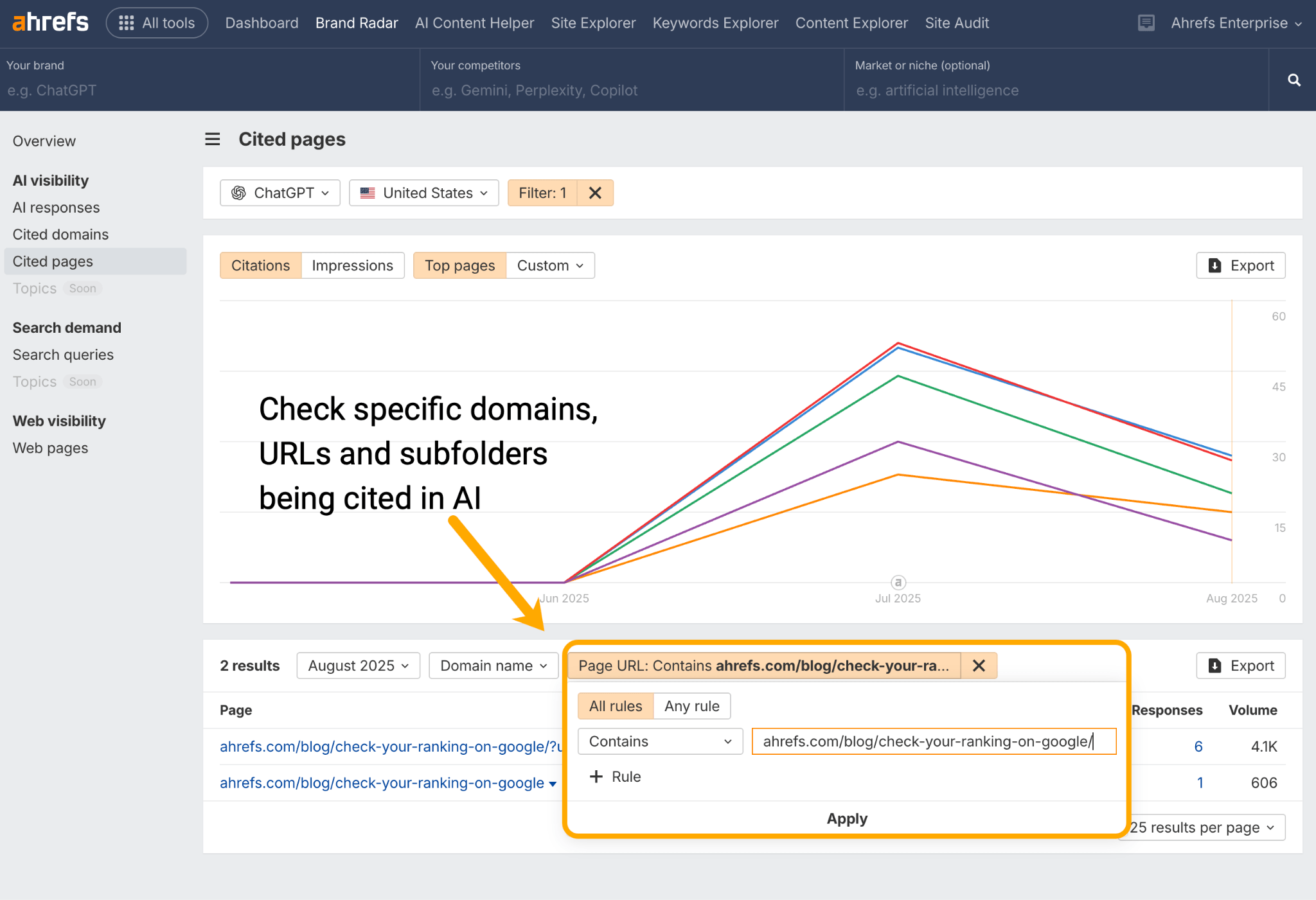
Identifiez si du contenu manque sur l’un ou l’autre des supports, puis optimisez jusqu’à combler ces lacunes et enrichir le cluster global.
Utilisez les recommandations de gap de sujet dans Ahrefs’ AI Content Helper pour vous aider dans cette tâche.
De tous les types de requêtes, les « Fan-out » montrent le moins de chevauchement de citations
Les requêtes courtes montrent une meilleure concordance entre les SERPs et l’AI que les requêtes en langage naturel—surtout pour Perplexity.
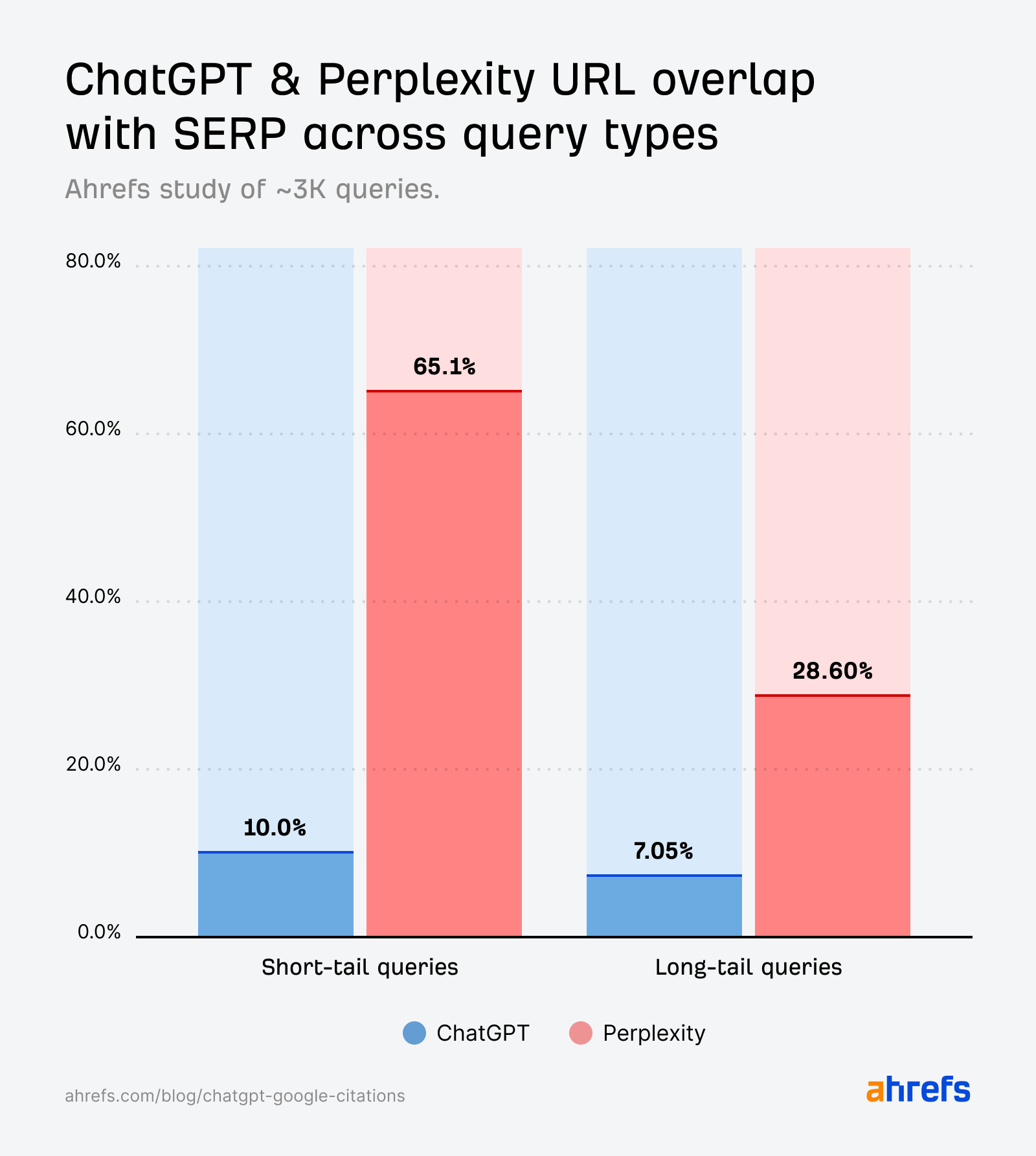
Toutefois, les citations de ChatGPT générées par les requêtes fan-out (étudiées pour la première fois par SQ et Xibeijia) montrent le moins de chevauchement. Elles correspondent à seulement 6,82% des 10 meilleurs résultats de Google.
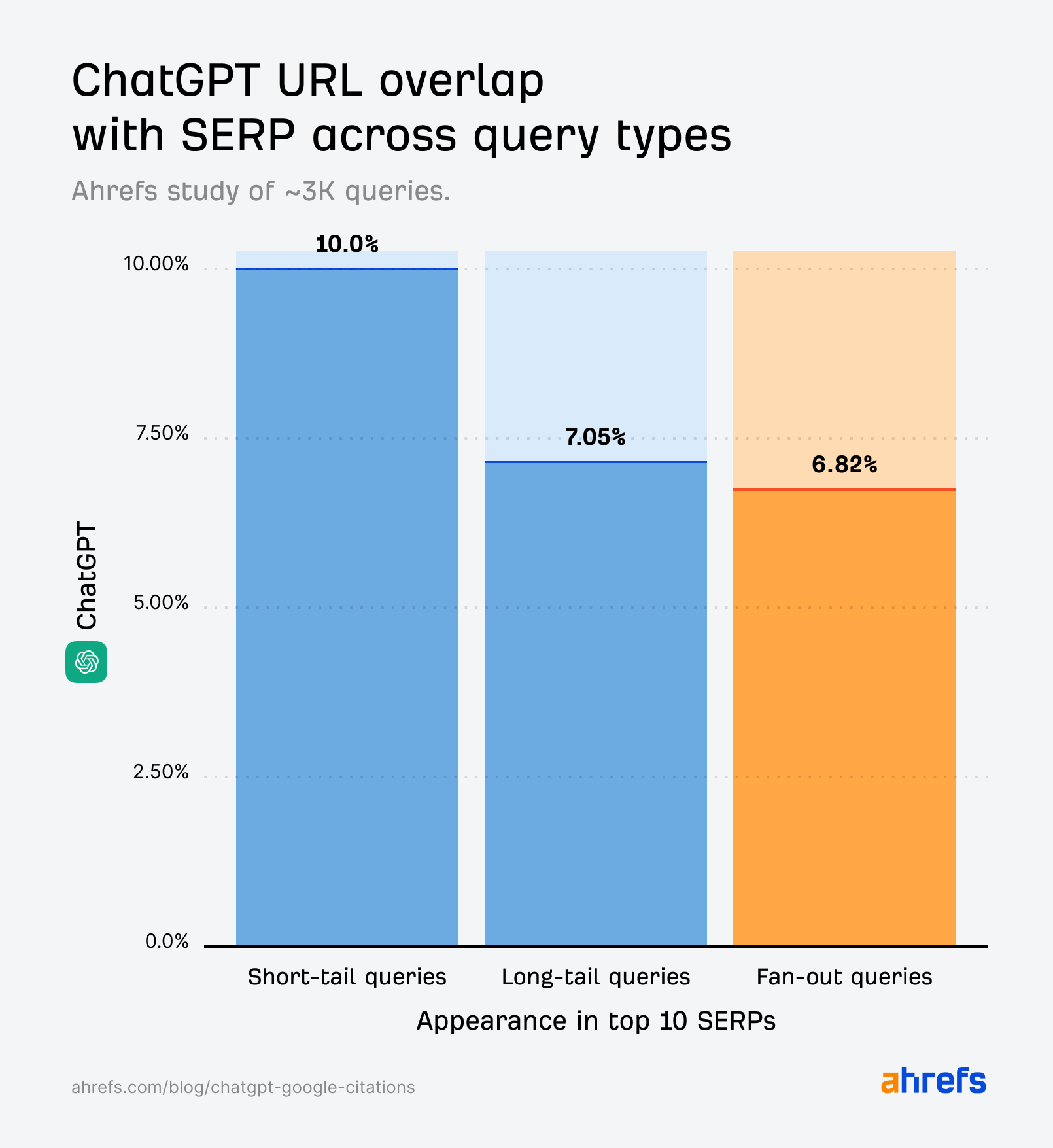
Nous ne comparons pas des pommes avec des pommes ici. Ces pourcentages représentent différentes études et ensembles de données de tailles différentes.
Mais chaque étude produit des résultats similaires : les pages que ChatGPT cite ne se chevauchent pas significativement avec celles que Google classe. Et c’est en grande partie l’inverse pour Perplexity.
Qu’en est-il de l’intention ?
Une autre chose que nous n’avons pas mentionnée est l’intention. Le chevauchement plus important des citations que nous constatons pour les requêtes courtes pourrait s’expliquer en partie par la stabilité relative des requêtes de navigation, commerciales et transactionnelles—que nous n’avons pas évaluées dans nos études précédentes.
Les termes courts de navigation, commerciaux et transactionnels ont des SERPs qui ne changent pas souvent, car l’ensemble des produits, marques ou destinations pertinentes est limité.
Cette stabilité signifie que les assistants AI et Google sont plus susceptibles de converger vers les mêmes sources, ce qui signifie que le chevauchement est plus élevé que pour les requêtes informatives (où le pool de pages possibles est beaucoup plus vaste et plus volatile).
Réflexions finales
À travers ces trois études, l’histoire est cohérente : ChatGPT ne suit pas les sources de Google, Perplexity le fait.
Ce qui est surprenant, c’est que ChatGPT diffère tellement de Google, alors que nous savons maintenant qu’OpenAI extrait les résultats de Google.
Mon intuition est que ChatGPT fait plus que Perplexity pour différencier son ensemble de résultats de ceux de Google.
Cette théorie de SQ me semble la plus probable :
“ChatGPT utilise probablement une approche hybride où il récupère des résultats de recherche de diverses sources, par exemple les SERPs de Google, les SERPs de Bing, son propre index, et des APIs de recherche tiers, puis combine toutes les URLs et applique son propre algorithme de re-classement.”
Quoi qu’il en soit, la recherche et l’AI façonnent la découverte côte à côte, et la meilleure stratégie est de créer du contenu vous permettant d’apparaître sur les deux surfaces.
